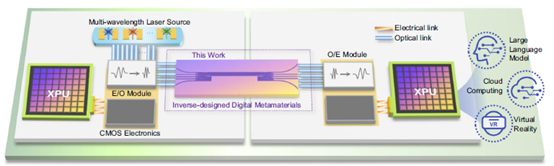
随着人工智能大模型参数规模呈指数级增长,智算芯片间与算力节点间的通信带宽瓶颈问题日益严峻。传统电子互连技术受限于物理特性,难以支撑GPU集群、超级计算中心及云计算平台对高速、高容量数据交换的需求。尤其在千亿级参数的大模型训练场景中,海量参数的跨节点同步传输常因带宽不足导致系统延迟激增甚至宕机,严重制约计算效率与模型迭代速度。
面对电子传输在带宽与能耗方面的物理限制,张江实验室与复旦大学联合研究团队通过精确设计和优化,将多维复用技术引入片上光互连架构,不仅显著提升了数据传输吞吐量,同时在功耗和延迟方面表现卓越,具备极强的扩展性和兼容性,适用于多种高性能计算场景。在此基础上,团队设计并研制了一款硅光集成高阶模式复用器芯片,实现了超大容量的片上光数据传输。实验结果表明,该芯片可支持每秒38Tb的数据传输速度,意味着未来1秒可完成大模型4.75万亿的参数传递,这显著提升了大模型训练与计算集群间的通信性能和可靠性,为人工智能、大模型训练及GPU加速计算等应用提供了强有力的支持。
这一技术突破不仅为数据中心和高性能计算服务器的光互连系统提供了新的解决方案,也为人工智能、大规模并行计算及大模型训练奠定了坚实的技术基础。相关研究成果已发表在国际期刊《自然·通讯》上。
论文链接:https://www.nature.com/articles/s41467-025-57689-7